


Problématique du jour
Un SIG est développé à partir d’une base de données PostgreSQL et de son extension spatiale PostGIS.
→ Pour ce tutoriel la BD s’appellera « Tutorial ».
Pour apprendre à créer une BD spatiale dans PostGIS, suivre le tutoriel Impuls’Map Créer une base de données spatiale avec PostgreSQL et PostGIS
Dans la BD « Tutorial », il y a 2 couches SIG :
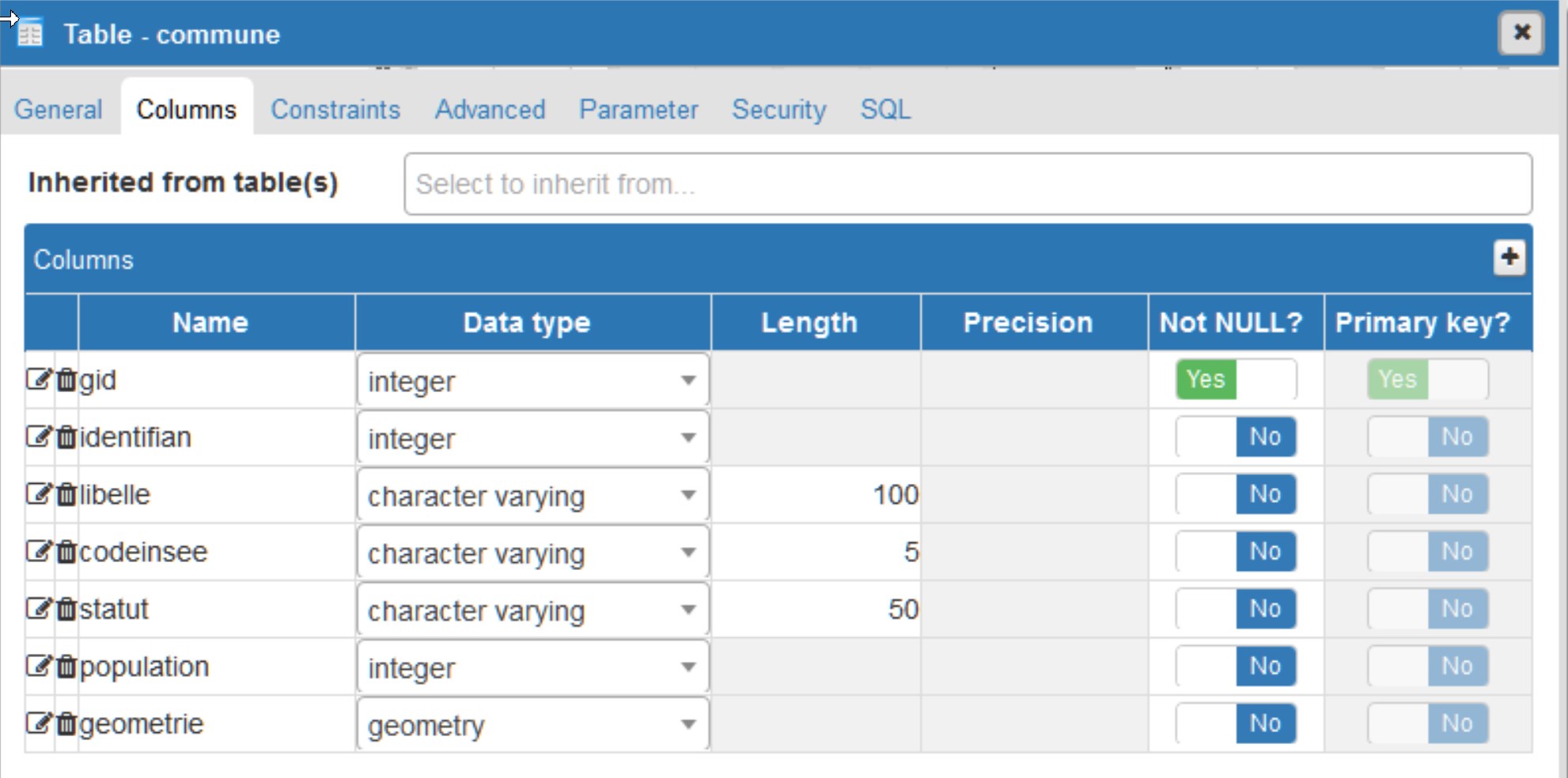
– la couche « Commune », de type polygone, qui décrit l’emprise de territoires administratifs,
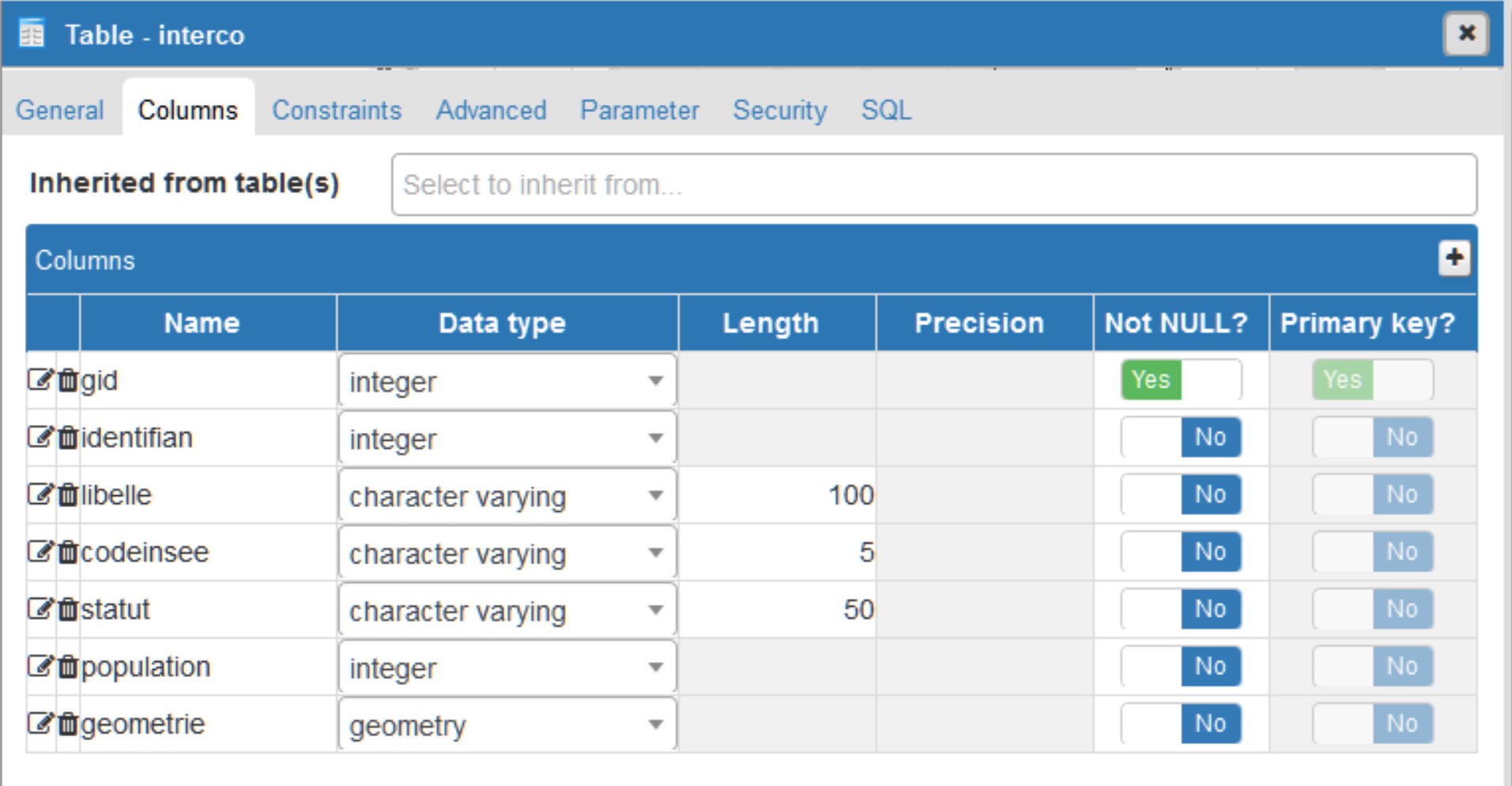
– la couche « Interco », de type polygone, qui décrit l’emprise de l’union de ces territoire.
Des modifications sont amenées à être effectuées au sein de ces 2 couches de données. On souhaite pouvoir enregistrer au sein d’une table de la BD « Tutorial » un suivi des modifications : création, mise à jour et suppression, effectuées sur ces 2 couches SIG.
La table où seront enregistrées ces actions sera appelée « suivi ».
Les pré-requis
Ce tutoriel admet donc comme pré-requis :
l’installation préalable du logiciel SGBD PostgreSQL et de l’extension spatiale PostGIS. Ce logiciel est libre et gratuit.
l’installation préalable d’un logiciel SIG permettant de lire des données PostGIS. L’utilisation d’un logiciel SIG n’est pas indispensable à la réalisation de ce tutoriel puisque les mises à jours peuvent être réalisées directement dans PostgreSQL. Mais nous utiliserons QGIS pour faciliter la visualisation des données exploitées et améliorer la compréhension du tutoriel. QGIS est un logiciel SIG gratuit et open source.
la détention de une ou plusieurs couches de données géographiques, intégrées dans une base de données PostGIS.
La mise en place d’un trigger PostgreSQL est valable aussi bien pour une comme plusieurs couches de données. Il peut s’agir de tables géographiques tout comme de tables simplement alpha-numériques. Si les données sont spatiales, elles peuvent être de tout type : point, polyligne ou polygone.
Pour ce tutoriel nous utiliserons 2 couches géographiques, de type polygone : « Commune » et « Interco ». Ce sont des données fictives..
la maîtrise des bases du langage SQL et de l’utilisation de pgAdmin. Ce tutoriel n’a pas vocation à vous apprendre ces deux aspects, mais à vous aider, à partir de vos connaissances de PostgreSQL/PostGIS et du SQL à mettre en place un trigger d’historisation des mises à jour.
Suivre le tutoriel pas à pas…
Étape 1 : Qu'est-ce qu'un trigger ?
Trigger est le terme anglophone pour signifier « déclencheur ».
Dans un contexte de gestion de base de données, les triggers sont des objets qui déclenchent l’exécution d’une instruction lorsqu’une action : insertion (INSERT), mise à jour (UPDATE) ou suppression (DELETE) est opérée sur la table à laquelle ils sont rattachés.
Les instructions peuvent être exécutées soit juste avant l’exécution – ex : BEFORE UPDATE – de l’événement déclencheur, soit juste après – ex : AFTER DELETE-.
Un trigger exécute un traitement pour chaque objet impacté par une action de type INSERT, UPDATE ou DELETE. Donc si on modifie 2 objets d’une table, les instructions déclenchées par le trigger seront exécutées deux fois. Chaque itération traitant les données de chaque ligne/objet l’un à la suite de l’autre.
L’utilisation d’un trigger peut avoir de nombreux objectifs. Et notamment celui de conserver une trace des opérations effectuées au sein d’une base de données. Ils permettent, en autre, de créer une historisation des actions souhaitées – l’instruction permettra de le paramétrer – pour réaliser un suivi. Ce suivi peut être réalisé au sein d’une table externe aux tables auxquelles seront affectés des triggers, ou au sein des tables elles-mêmes.
Afin d’alléger les données, de permettre plus de flexibilité et de centraliser cette historisation, pour ce tutoriel, les actions réalisées seront enregistrées au sein d’une table appelée « suivi ».
Étape 2 : Présentation des données utilisées
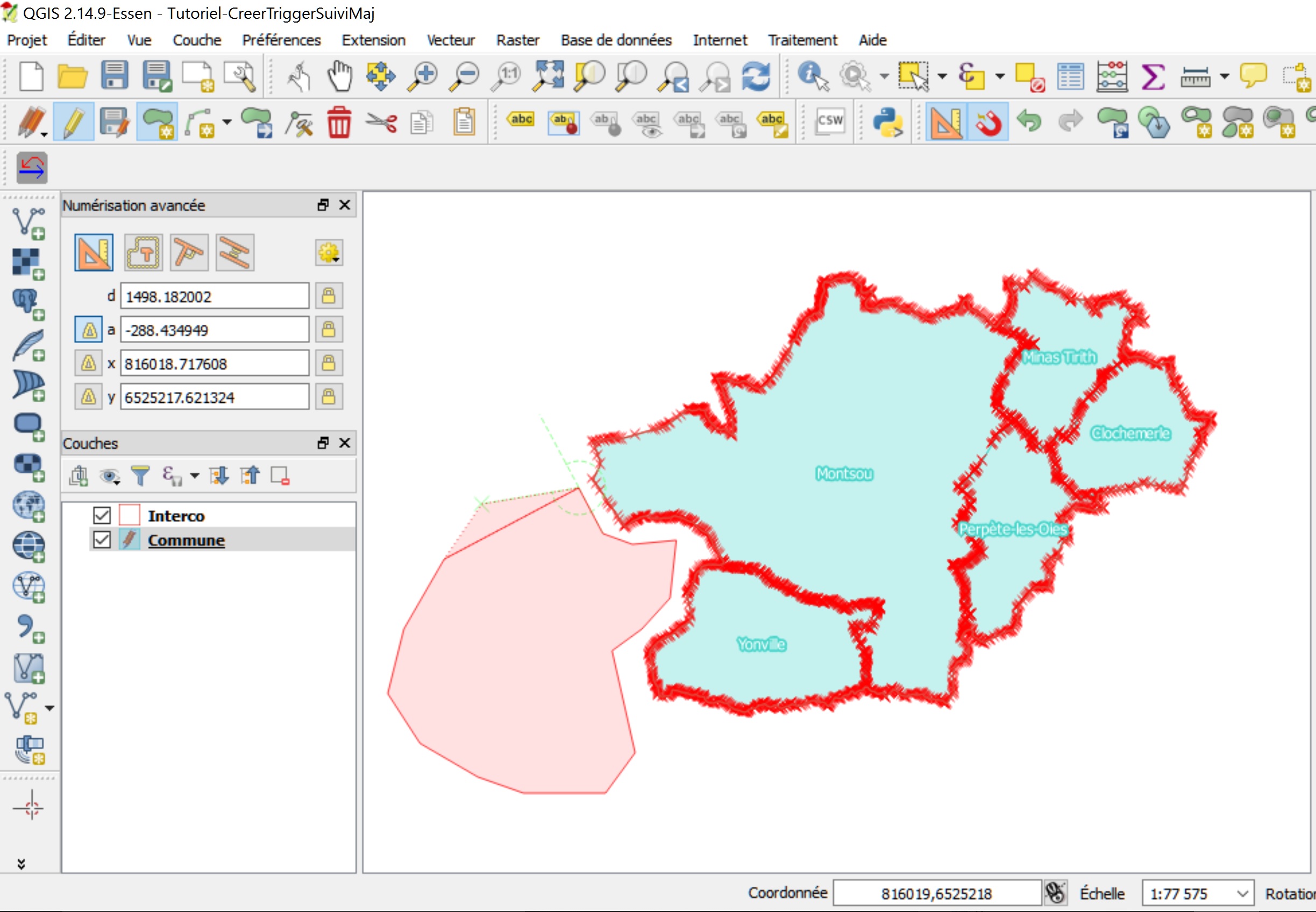
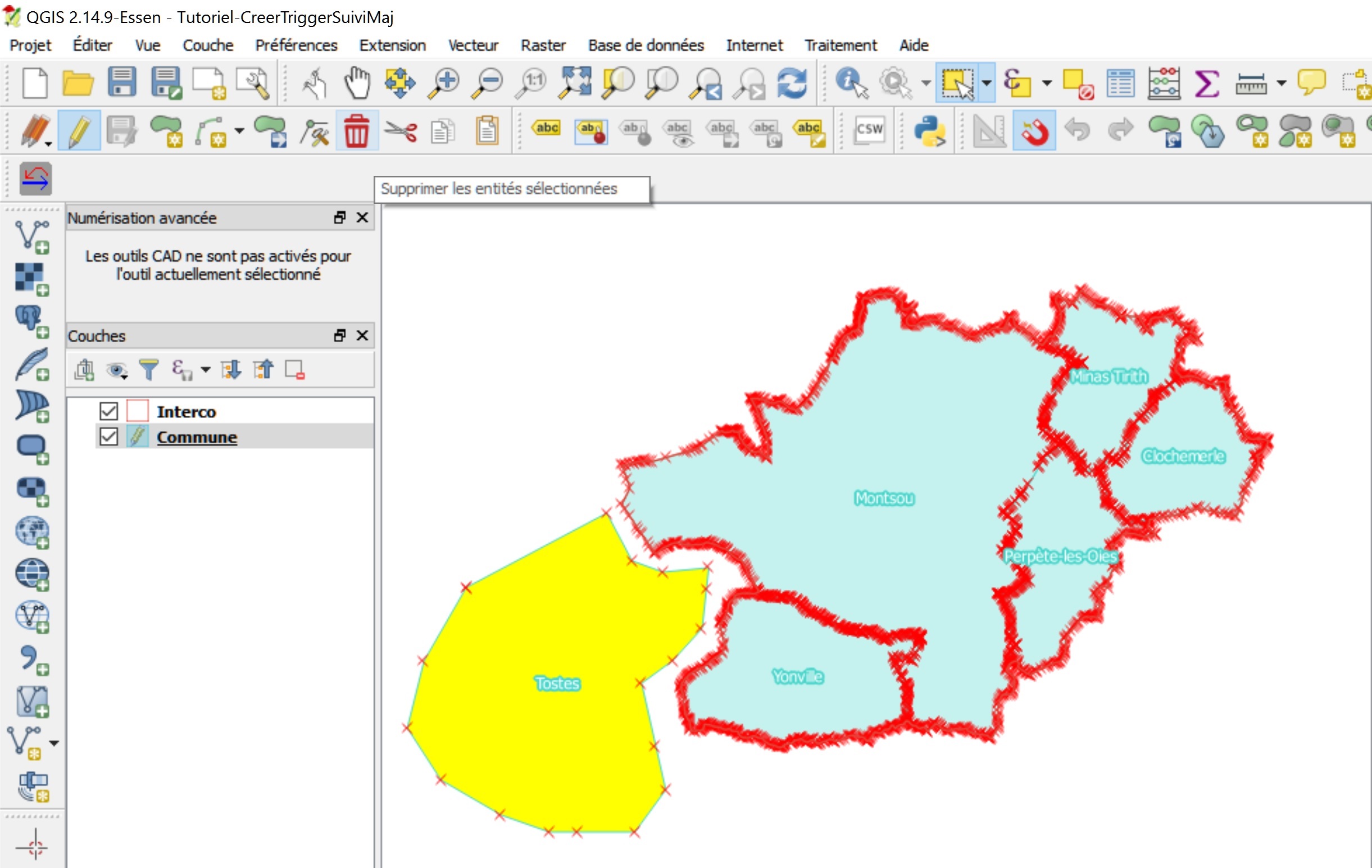
Pour ce tutoriel, les données utilisées sont deux couches PostGIS de type polygone.
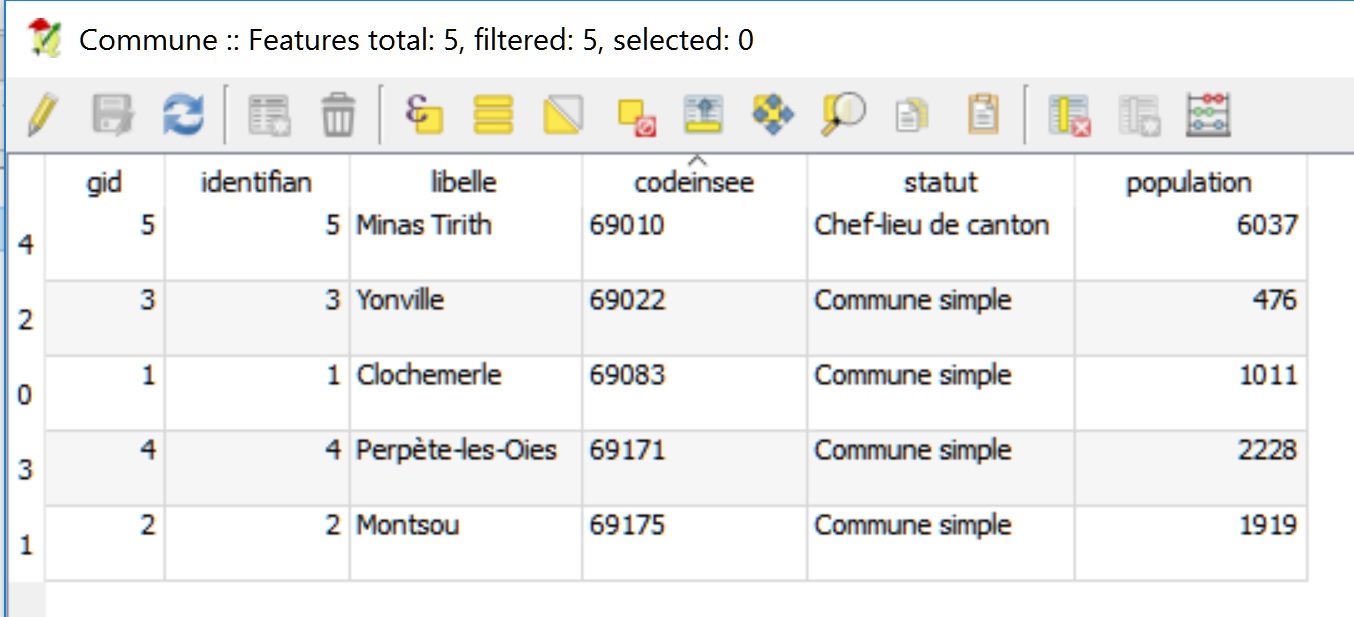
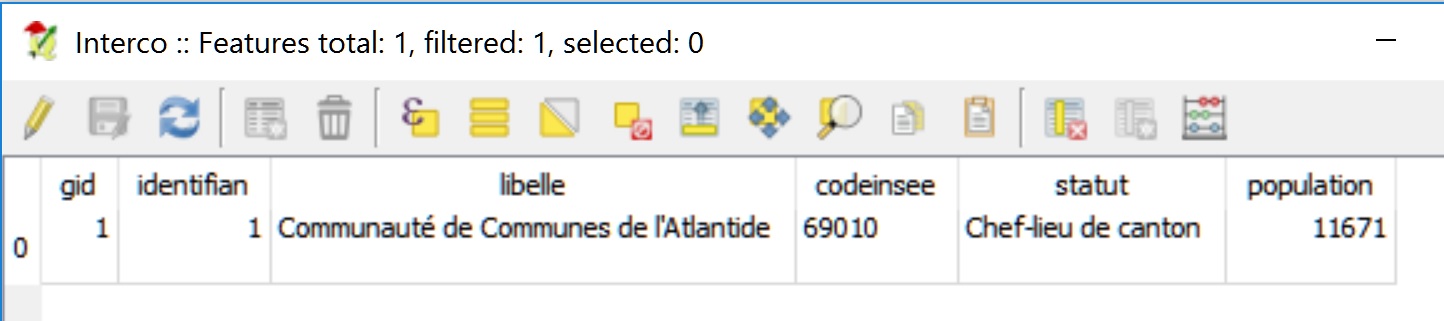
La couche « Commune » décrit l’emprise de territoires administratifs fictifs, et la couche « Interco » décrit l’emprise de l’union de ces territoires.
On peut en voir ci-dessous une visualisation dans le logiciel SIG QGIS.
Pour apprendre à ouvrir des données vectorielles gérées au sein du SGBD PostgreSQL et son extension spatiale PostGIS dans QGIS, lire le tutoriel Impuls’Map Afficher des données PostGIS dans QGIS

Les structures de ces deux tables sont décrites grâce aux images ci-dessous :
Couche « Commune »
Couche « Interco »
Étape 3 : Structure de la table suivi qui contiendra l'historisation des actions
Dans le contexte de ce tutoriel, il est décidé de centraliser l’ensemble des actions opérées sur les 2 couches « Interco » et « Commune » de la BD « Tutoriel » au sein d’une seule table. Cette table est nommée « suivi ».
Afin de stocker les informations d’historisation : table concernée par l’action, utilisateur, type d’action, ancienne valeur, nouvelle valeur, date et heure de la mise à jour, détail de la requête envoyée au SGBD, identifiant de l’objet mis à jour… La table suivi aura la structure suivante :
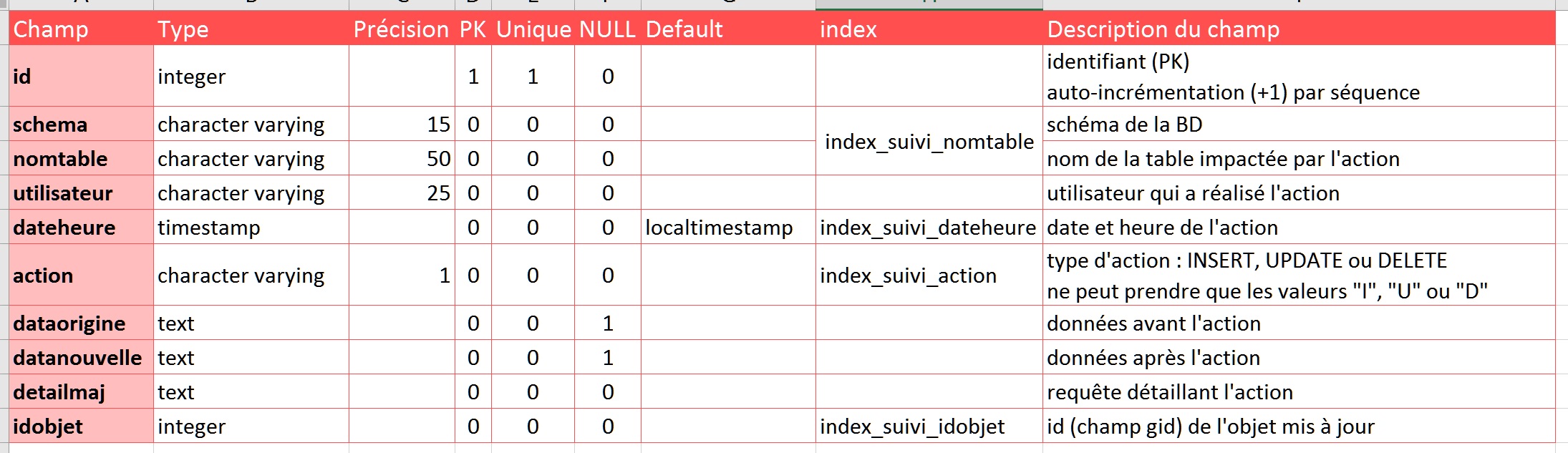
Pour ce tutoriel, l’ensemble des actions serons réalisées directement en SQL.
Mais il est possible, grâce à l’interface PgAdmin – aujourd’hui dans sa version 4 –, de créer tables, séquences, fonctions, index et triggers de manière assistée.
Etape 4 : Création de la séquence d'auto-incrémentation du champ identifiant de la table suivi
Au sein de la table « suivi », le champ identifiant « id » doit être alimenté grâce à une auto-incrémentation opérant de 1 en 1.
Pour la réaliser, nous allons utiliser une séquence.
La séquence est nommée « sequence_suivi_id »,
« MINVALUE » → Sa valeur minimal est « 1 » → la valeur la plus basse du champ « id » sera « 1 »,
« MAXVALUE » → Sa valeur maximal est « 1.000.000 » → la valeur la plus élevée pouvant être prise par le champ « id » sera « 1.000.000 »,
« START » → c’est le compteur de la séquence, il enregistre la dernière valeur prise par le champ « id »,
« INCREMENT » → paliers d’incrémentation → le champ « id » évoluera de 1 en 1
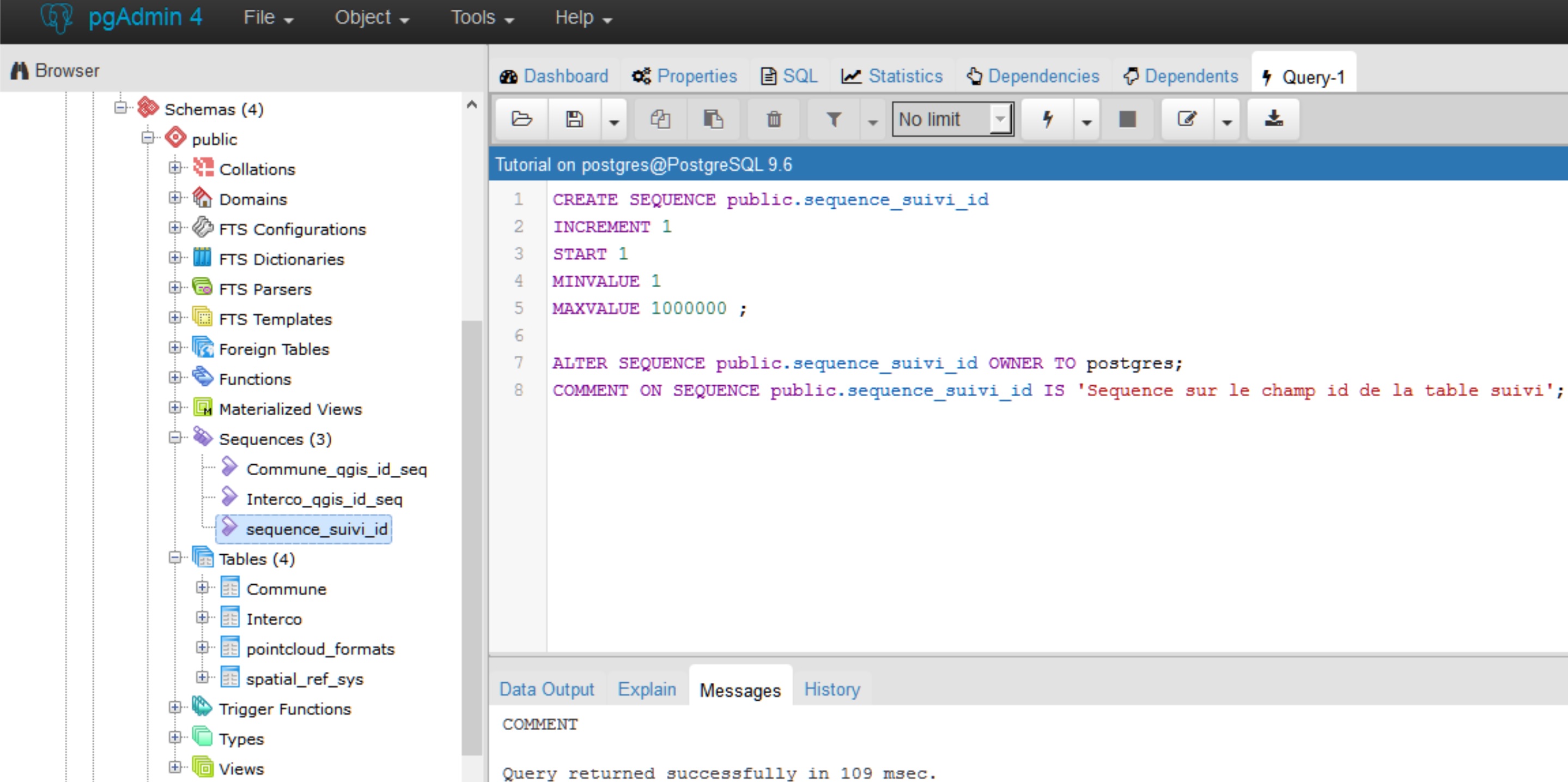
CODE SQL pour créer la séquence
CREATE SEQUENCE public.sequence_suivi_id INCREMENT 1 START 1 MINVALUE 1 MAXVALUE 1000000 ; ALTER SEQUENCE public.sequence_suivi_id OWNER TO postgres; COMMENT ON SEQUENCE public.sequence_suivi_id IS 'Sequence sur le champ id de la table suivi';
Dans une fenêtre SQL de pgAdmin, rédiger la requête décrite ci-dessus.
Pour l’exécuter, cliquer sur le bouton Exécuter ou F5
Effectuer un F5/Refresh sur les Séquences du schéma public et constater que la séquence sequence_suivi_id a bien été créée.

Étape 5 : Création de la table suivi
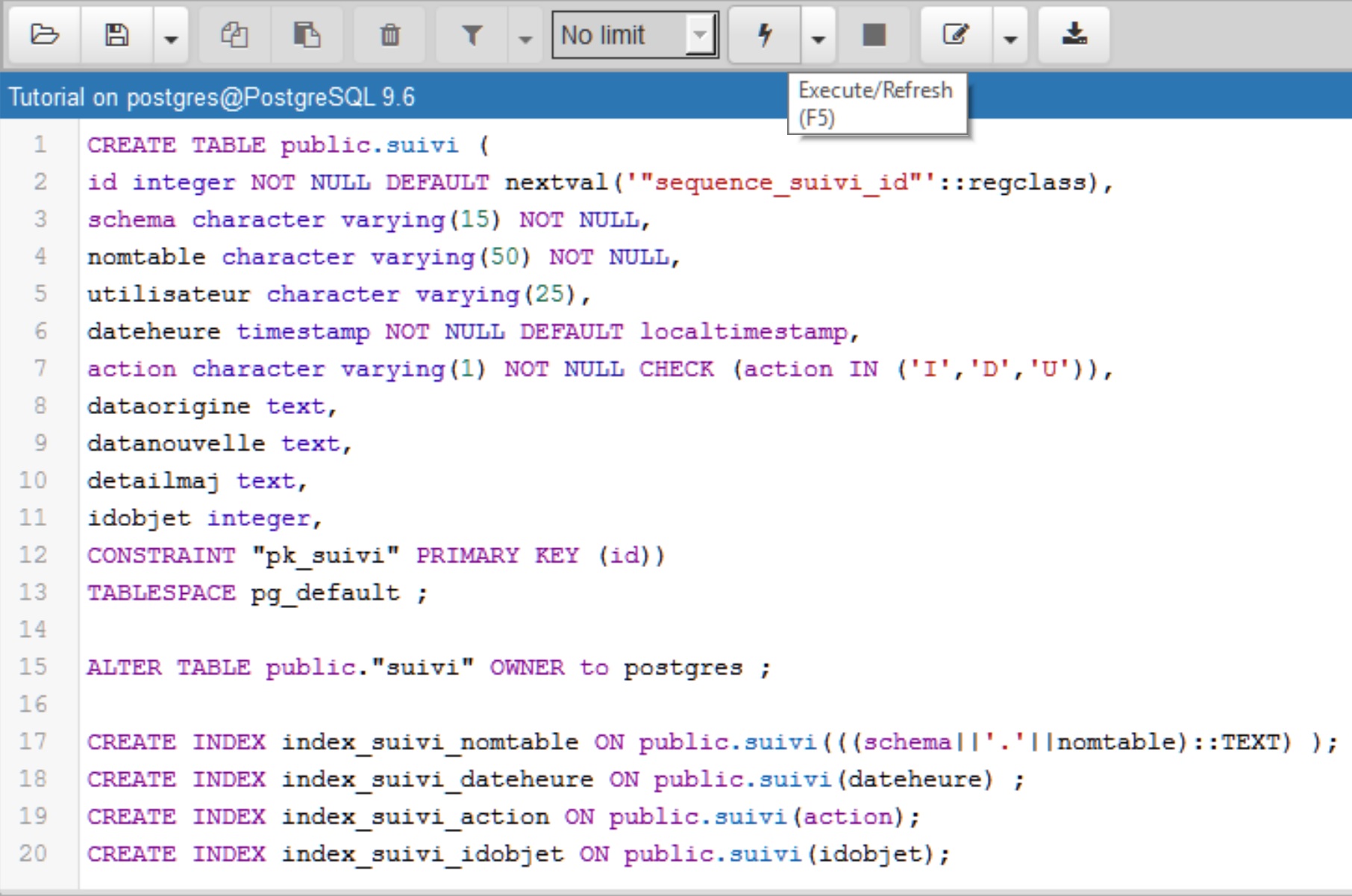
Voici le code SQL pour créer la table suivi telle que sa structure est décrite au sein de l’Étape 3 : Structure de la table suivi qui contiendra l’historisation des actions.
La première étape CREATE TABLE permet de créer la table suivi au sein du schéma public, ainsi que les différents champs qui la compose : leur type, précision, éventuelles contraintes (NULL, valeur par défaut → DEFAULT, valeurs pouvant être prises par un champ → CHECK, séquence, clé primaire → CONSTRAINT … PRIMARY KEY).
La deuxième étape CREATE INDEX permet d’indexer certains champs de la table suivi.
CREATE TABLE public.suivi ( id integer NOT NULL DEFAULT nextval('"sequence_suivi_id"'::regclass), schema character varying(15) NOT NULL, nomtable character varying(50) NOT NULL, utilisateur character varying(25), dateheure timestamp NOT NULL DEFAULT localtimestamp, action character varying(1) NOT NULL CHECK (action IN ('I','D','U')), dataorigine text, datanouvelle text, detailmaj text, idobjet integer, CONSTRAINT "pk_suivi" PRIMARY KEY (id)) TABLESPACE pg_default ;
ALTER TABLE public."suivi" OWNER to postgres ; CREATE INDEX index_suivi_nomtable ON public.suivi(((schema||'.'||nomtable)::TEXT) ); CREATE INDEX index_suivi_dateheure ON public.suivi(dateheure) ; CREATE INDEX index_suivi_action ON public.suivi(action); CREATE INDEX index_suivi_idobjet ON public.suivi(idobjet);
Dans une fenêtre SQL de pgAdmin, rédiger la requête décrite ci-dessus.
Pour l’exécuter, cliquer sur le bouton Exécuter ou F5
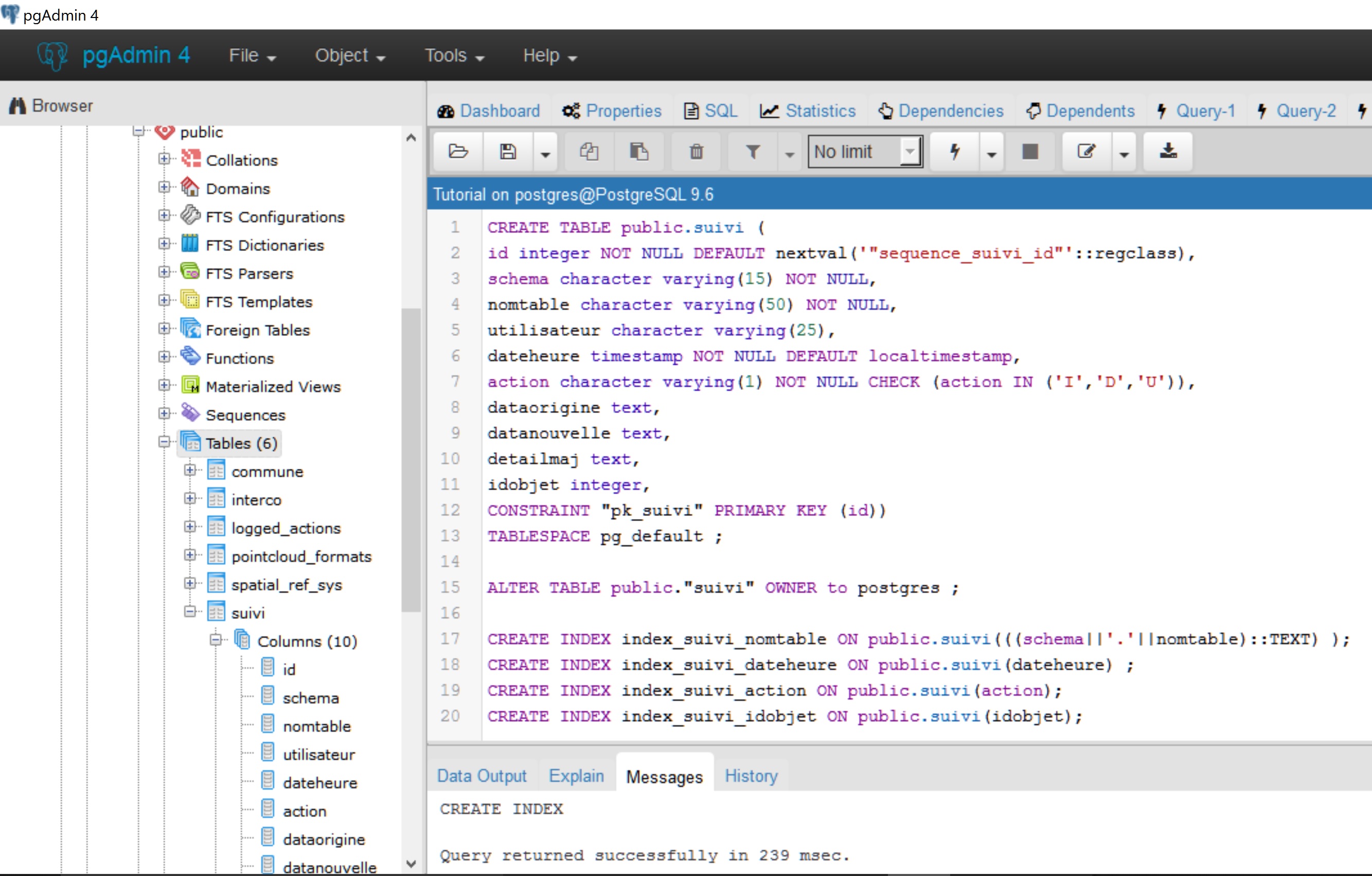
Effectuer un F5/Refresh sur les Tables du schéma public et constater que la table suivi a bien été créée.
Étape 6 : Création de la fonction détaillant les instructions déclenchées par le trigger
La table suivi qui va stocker l’historisation des actions menées au sein des couches Commune et Interco de la BD Tutorial est maintenant créée.
L’étape suivante consiste à créer la fonction qui va réaliser les instructions qui seront déclenchées par le trigger.
C’est cette fonction qui va permettre d’indiquer la manière dont doit être remplie la table suivi.
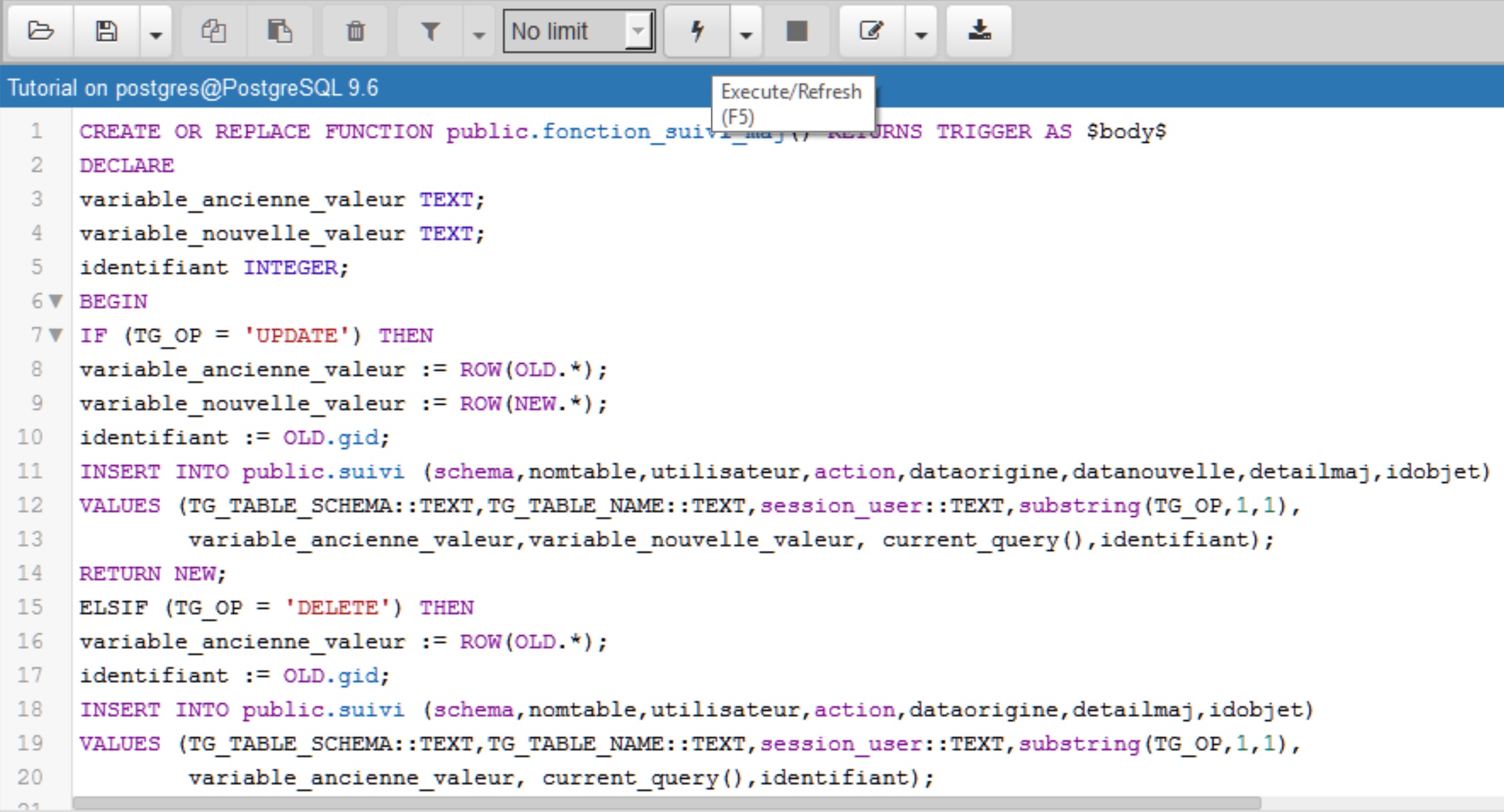
La fonction créée s’appelle fonction_suivi_maj
Les variables variable_ancienne_valeur et variable_nouvelle_valeur permettent de stocker temporairement le temps de l’exécution de la fonction, puis définitivement dans la table suivi, les valeurs originelles des données avant l’action (INSERT, UPDATE ou DELETE), et les valeurs prises par les données après l’action.
La variable identifiant va permettre de stocker l’information de l’id de l’objet concerné par la mise à jour. Nous souhaitons que la fonction puisse servir à historiser les mises à jour de plusieurs tables. Pour que cela soit possible, il faut qu’elles possèdent toutes le même nom de champ id. Pour la BD Tutorial, toutes les couches géographiques ont un champ gid qui s’alimente par incrémentation automatique grâce à une séquence.
TG_OP → permet de connaître le type d’opération lancé par le trigger
TG_TABLE_SCHEMA → renvoie le nom du schéma de la table qui a provoqué le déclenchement du trigger
TG_TABLE_NAME → renvoie le nom de la table qui a provoqué le déclenchement du trigger
session_user → renvoie l’utilisateur à l’origine de l’action
current_query() → renvoie le texte SQL de la requête de mise à jour effectuée sur la table à laquelle est rattachée le trigger
La fonction substring est une fonction de type chaîne. Elle extrait une sous-chaîne de caractère.
Son fonctionnement est substring(chaîne, position du 1er caractère qu’on souhaite extraire, nombre de caractères à extraire). Par exemple
substring('DELETE',1,1) = 'D'
RAISE permet de rapporter des messages ou des erreurs
SECURITY DEFINER précise que la fonction doit être exécutée avec les droits de l’utilisateur qui l’a créée
Code SQL
CREATE OR REPLACE FUNCTION public.fonction_suivi_maj() RETURNS TRIGGER AS $body$ DECLARE variable_ancienne_valeur TEXT; variable_nouvelle_valeur TEXT; identifiant INTEGER; BEGIN IF (TG_OP = 'UPDATE') THEN variable_ancienne_valeur := ROW(OLD.*); variable_nouvelle_valeur := ROW(NEW.*); identifiant := OLD.gid; INSERT INTO public.suivi (schema,nomtable, utilisateur, action, dataorigine, datanouvelle, detailmaj, idobjet) VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user::TEXT, substring(TG_OP,1,1), variable_ancienne_valeur, variable_nouvelle_valeur, current_query(), identifiant); RETURN NEW; ELSIF (TG_OP = 'DELETE') THEN variable_ancienne_valeur := ROW(OLD.*); identifiant := OLD.gid; INSERT INTO public.suivi (schema, nomtable, utilisateur, action, dataorigine, detailmaj, idobjet) VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user::TEXT, substring(TG_OP,1,1), variable_ancienne_valeur, current_query(), identifiant); RETURN OLD; ELSIF (TG_OP = 'INSERT') THEN variable_nouvelle_valeur := ROW(NEW.*); identifiant := NEW.gid; INSERT INTO public.suivi (schema, nomtable, utilisateur, action, datanouvelle, detailmaj, idobjet) VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user::TEXT, substring(TG_OP,1,1), variable_nouvelle_valeur, current_query(), identifiant); RETURN NEW; ELSE RAISE WARNING '[public.fonction_suivi_maj] - Other action occurred: %, at %', TG_OP,now(); RETURN NULL; END IF; END; $body$ LANGUAGE plpgsql SECURITY DEFINER SET search_path = pg_catalog, public;
Dans une fenêtre SQL de pgAdmin, rédiger la requête décrite ci-dessus.
Pour l’exécuter, cliquer sur le bouton Exécuter ou F5
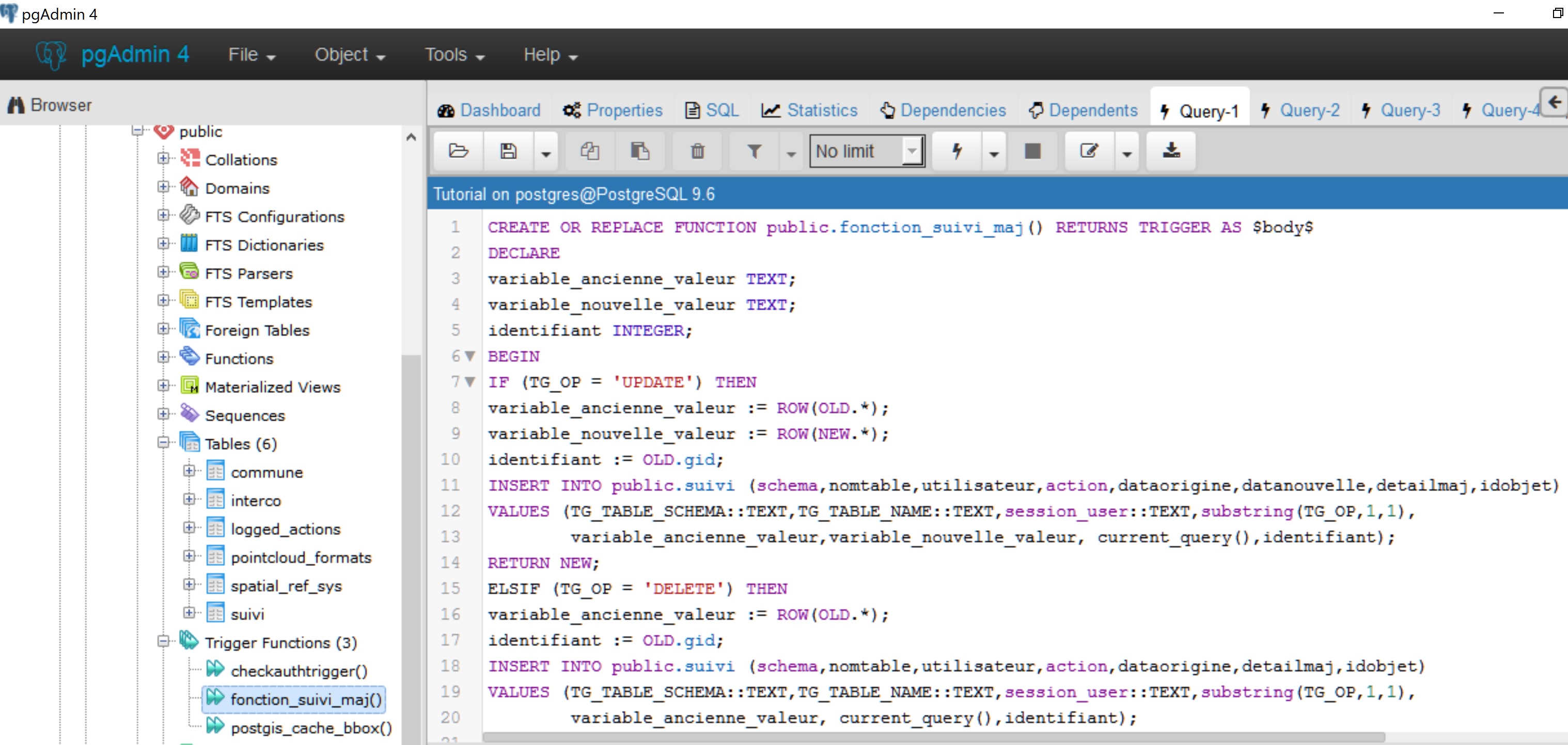
Effectuer un F5/Refresh sur les Trigger Functions du schéma public et constater que la fonction fonction_suivi_maj() a bien été créée.
Étape 7 : Création du trigger
Lorsque la fonction déclenchée par le trigger est créée, il reste à créer le trigger en lui même et à lui attribuer les actions qui le déclencheront, ainsi qu’une table de rattachement.
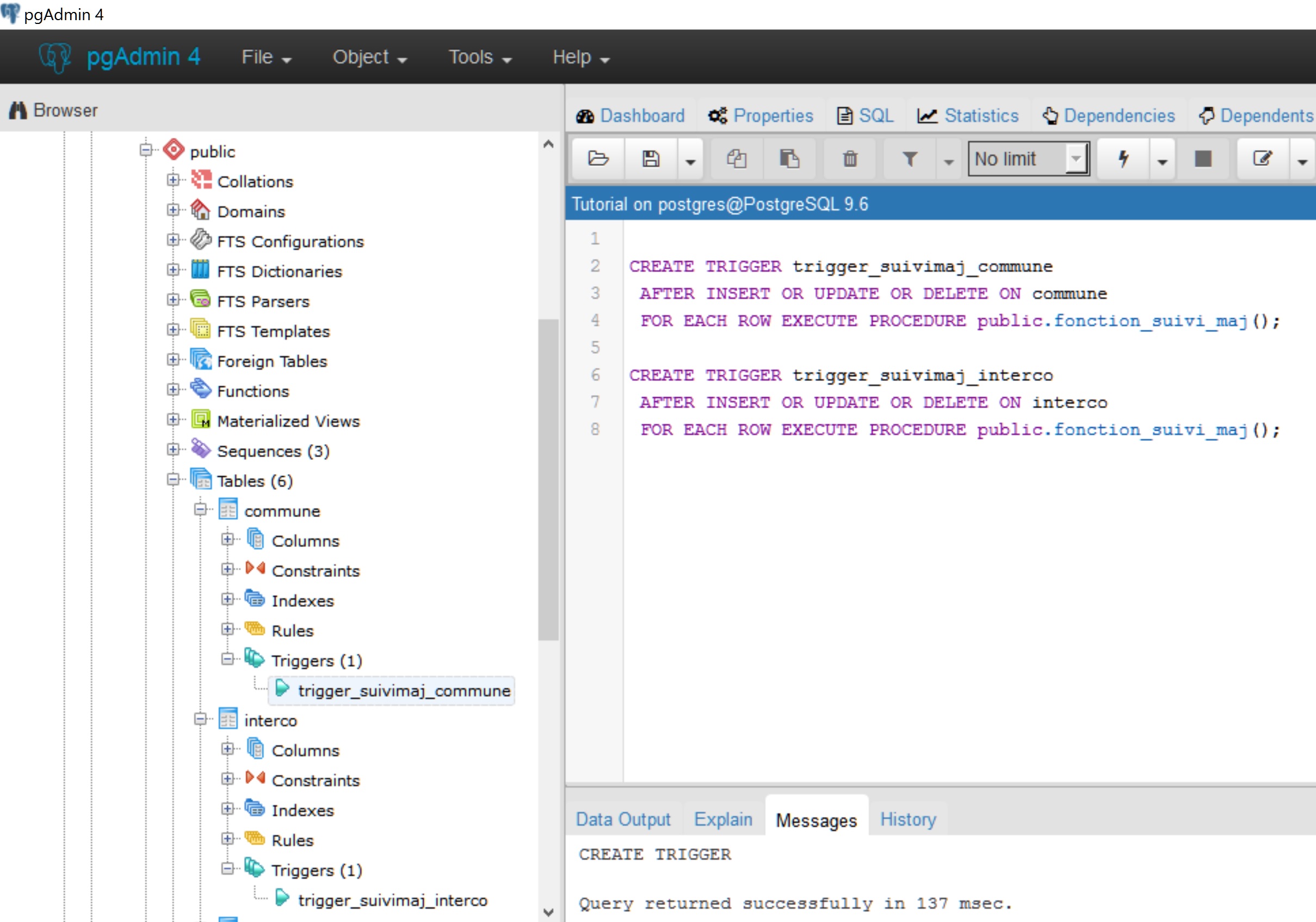
Les deux triggers créés s’appellent trigger_suivimaj_commune et trigger_suivimaj_interco.
Ils sont respectivement rattachés aux tables commune et interco.
Ce qui signifie que ces deux tables déclenchent une fonction.
Les actions de déclenchement sont INSERT, DELETE et UPDATE. Ainsi toute mise à jour déclenche la fonction et permettra une historisation au sein de la table suivi.
Nous aurions pu créer des triggers qui ne se déclenchent que sur un seul type d’action.
Les deux triggers déclenchent la même fonction fonction_suivi_maj().
Il n’est pas nécessaire de créer une fonction pour chaque trigger. D’autant plus que dans le cas de ce tutoriel, on souhaite mettre en place strictement les mêmes instructions lors de mises à jour sur les tables.
Code SQL
CREATE TRIGGER trigger_suivimaj_commune AFTER INSERT OR UPDATE OR DELETE ON commune FOR EACH ROW EXECUTE PROCEDURE public.fonction_suivi_maj(); CREATE TRIGGER trigger_suivimaj_interco AFTER INSERT OR UPDATE OR DELETE ON interco FOR EACH ROW EXECUTE PROCEDURE public.fonction_suivi_maj();
Dans une fenêtre SQL de pgAdmin, rédiger la requête décrite ci-dessus.
Pour l’exécuter, cliquer sur le bouton Exécuter ou F5
Effectuer un F5/Refresh sur les tables commune et interco du schéma public et constater que les triggers trigger_suivimaj_commune et trigger_suivimaj_interco ont bien été créés.

Étape 8 : Vérification du bon fonctionnement de l'historisation des mises à jour... et donc des triggers
Afin de tester le bon fonctionnement de l’historisation des mises à jour au sein de la BD Tutorial pour les 2 couches SIG commune et interco – et donc du bon fonctionnement des triggers et de la fonction qu’ils déclenchent – nous allons tester les 3 types d’action possibles :
– INSERT,
– UPDATE,
– DELETE.
Ces modifications peuvent être faites directement / uniquement dans PostgreSQL mais pour une meilleure visibilité, nous les ferons dans le logiciel SIG QGIS.
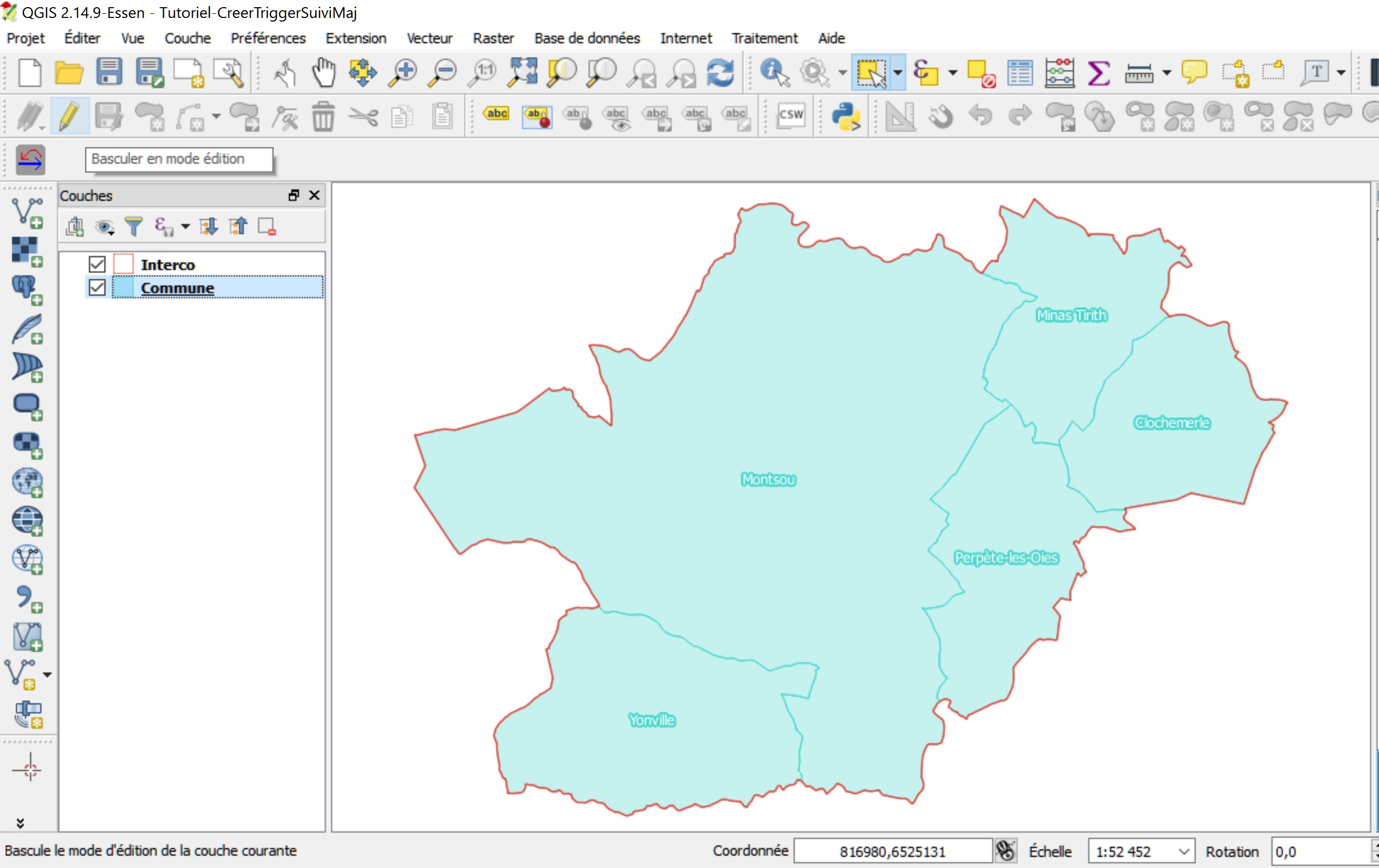
Ouvrir les couches PostGIS commune et interco dans QGIS.
Réalisation d’une action d’insertion (INSERT)
Basculer la couche commune en mode Édition.
Créer une nouvelle commune en dessinant un nouveau polygone et lui attribuer des données attributaires.
Stopper l’édition et enregistrer les mises à jour.
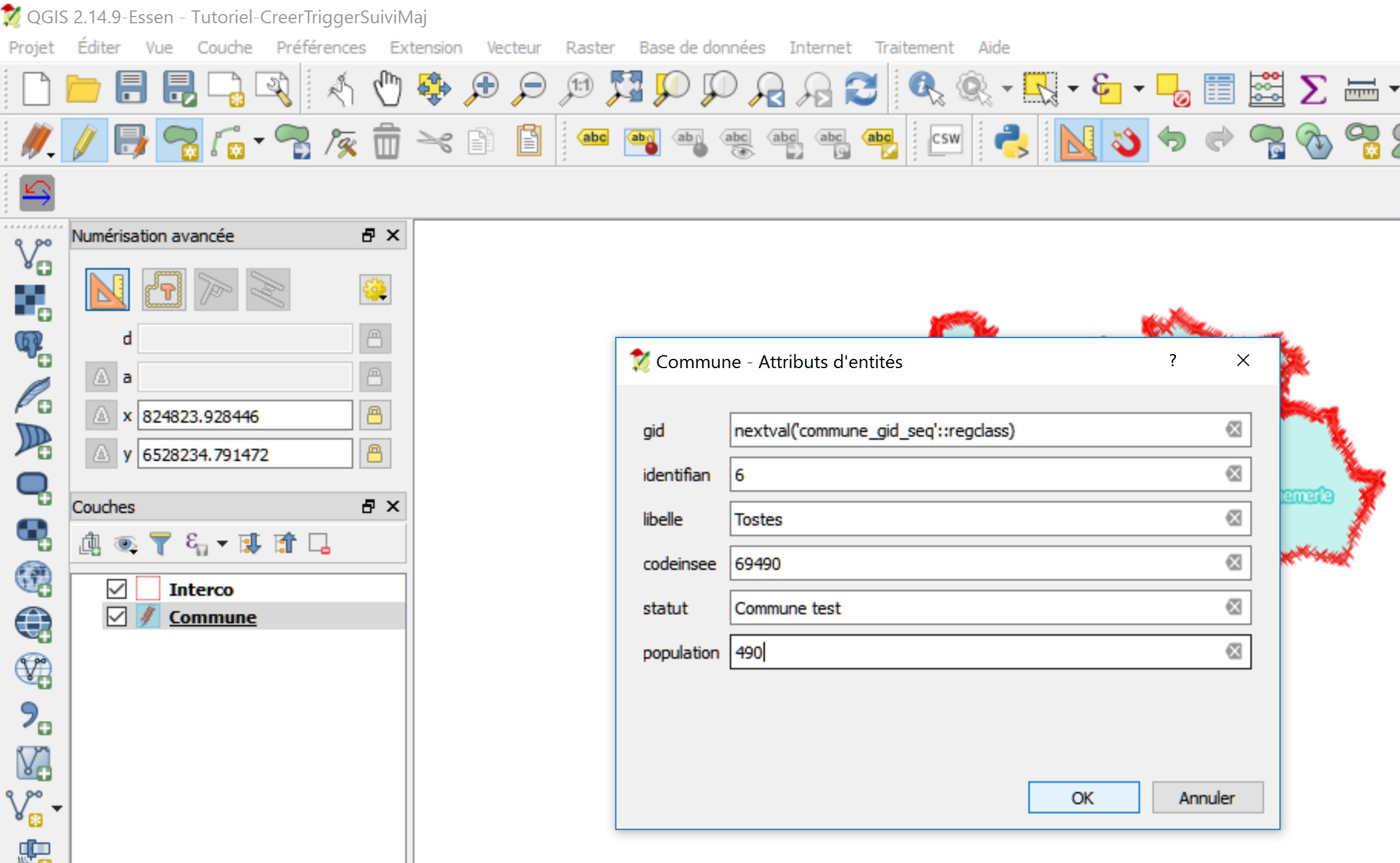
Réalisation d’une action de mise à jour de type UPDATE
Basculer la couche interco en mode Édition
Ouvrir les données attributaires et modifier la valeur du champ population puis quitter le mode Édition et enregistrer les mises à jour
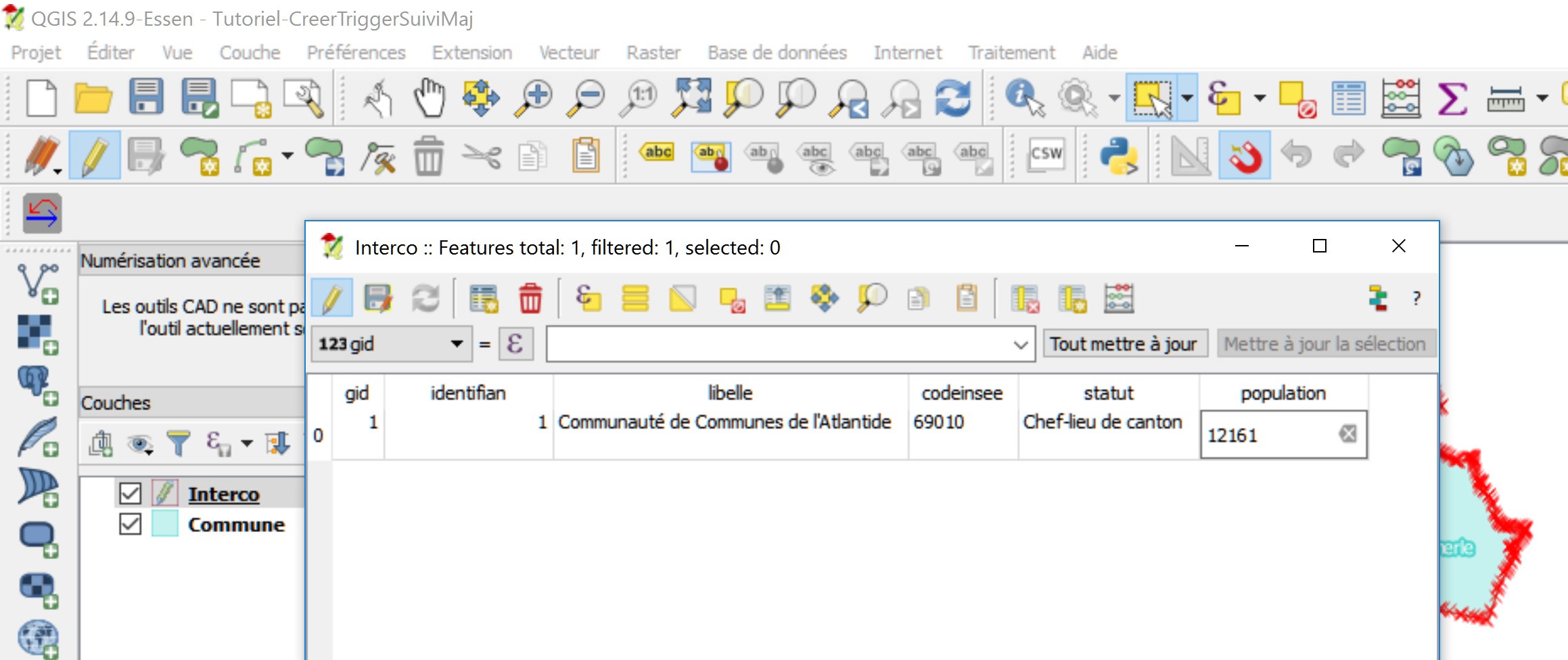
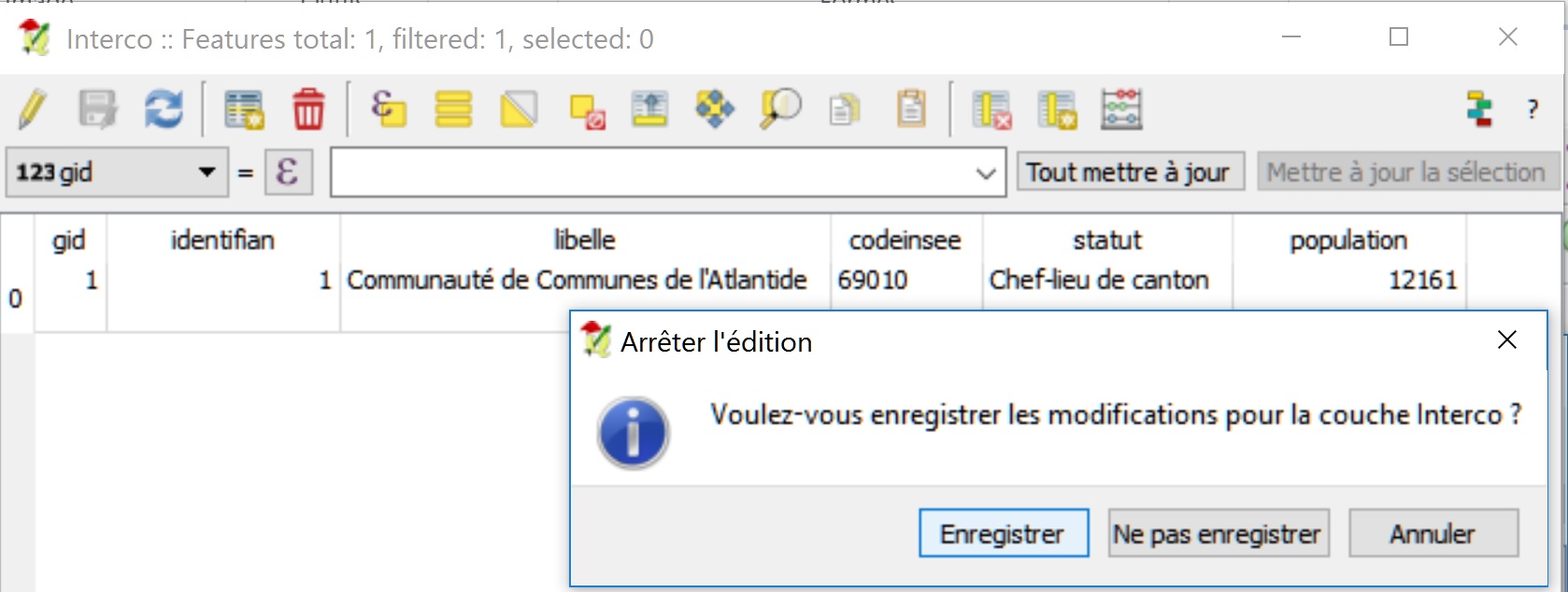
Réalisation d’une action de suppression (DELETE)
Basculer la couche commune en mode Édition
Supprimer la commune que vous venez de créer – pour ce tutoriel, celle dont le libelle est « Tostes » –
Sortir du mode Édition et enregistrer les mises à jour
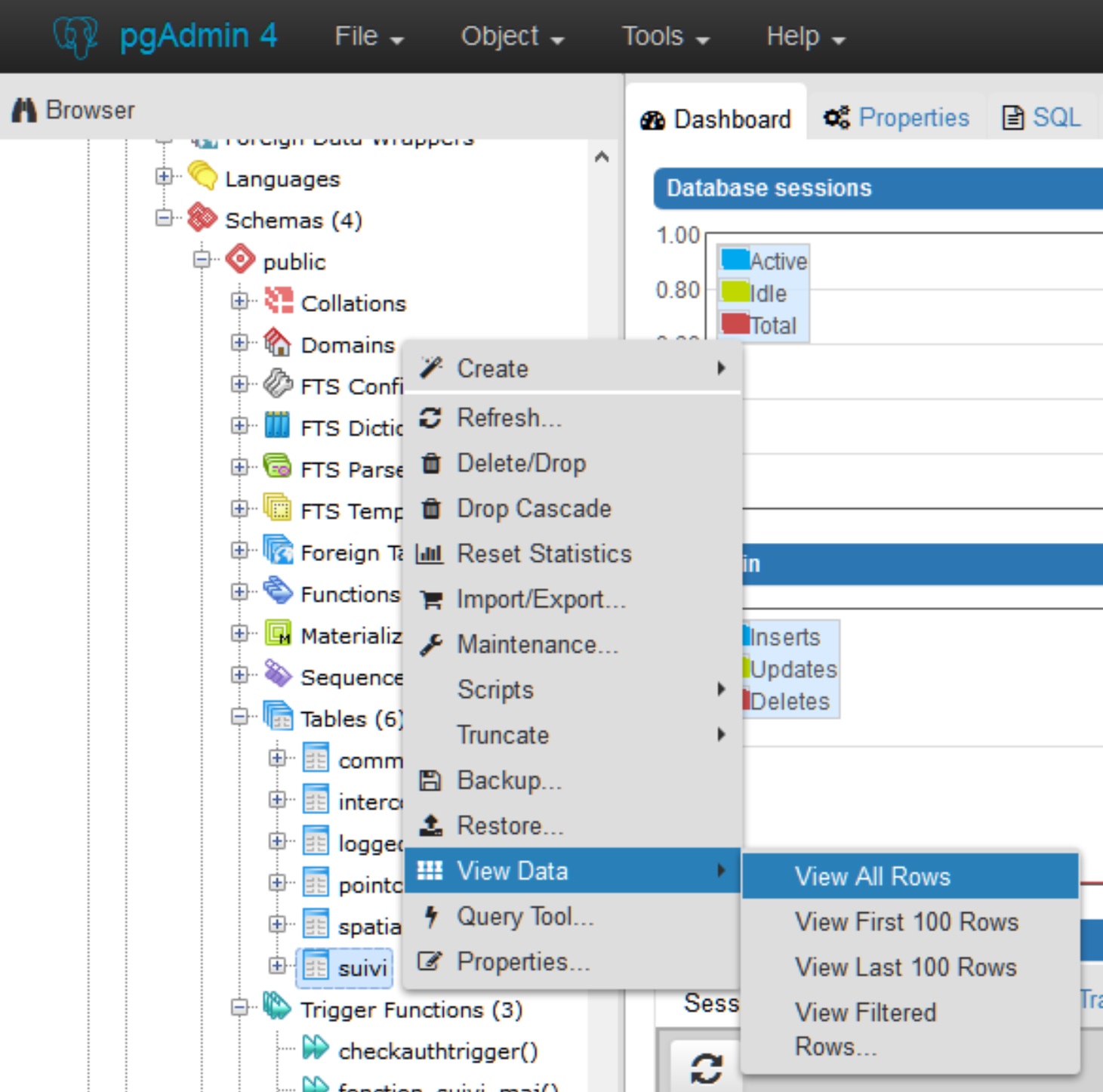
Dans PostgreSQL, notamment via pgAdmin…
Visualiser les données de la table public.suivi
Soit en effectuant un clic-droit sur la table suivi > View Data > View All Rows
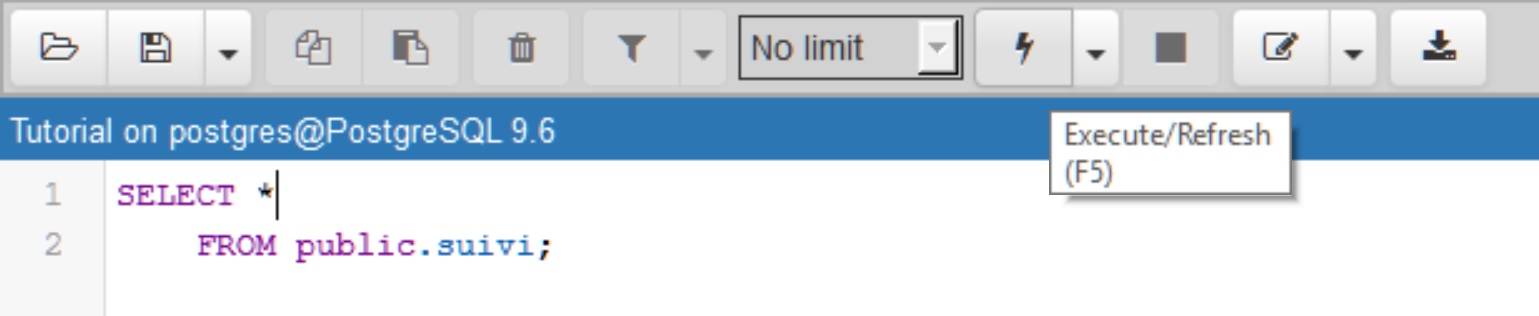
Soit en exécutant dans une fenêtre SQL la requête > SELECT * FROM public.suivi ;
On constate qu’une entrée a été créée dans la table public.suivi pour les 3 actions (INSERT, UPDATE et DELETE) réalisées au sein soit de la couche commune soit de la couche interco.
Il est possible de savoir quelle table a subi une mise à jour, depuis quel utilisateur, quel type d’action a déclenché la fonction, quel jour et à quelle heure la mise à jour a été effectuée, quelles étaient les valeurs des champs à l’origine et les valeurs qu’ils ont pris après l’action, le détail de la requête de mise à jour qui a été exécutée, et l’identifiant de l’objet concerné par la mise à jour.

Étape 10 : De l'utilisation des données personnelles
Au sein de ce tutoriel, nous avons créé un trigger qui permet de stocker l’historisation des actions ayant lieu sur les tables d’une base de données.
Nous avons notamment pris le parti d’enregistrer l’utilisateur qui effectue chaque action. Car nous souhaitions être exhaustif dans l’ensemble des fonctionnalités présentées.
Stocker l’utilisateur qui a effectué les mises à jour présente parfois un intérêt de démarche qualité, mais cette utilisation est encadrée. Vous devez, si cet utilisateur « base de données » peut être rattaché à une ou plusieurs personnes :
– effectuer une déclaration auprès de la CNIL puisqu’il y a un traitement de données personnelles,
– avertir vos utilisateurs que leurs actions font l’objet d’un traitement.
Pour + d’informations, vous pouvez vous rendre sur le site web de la CNIL www.cnil.fr

Ce tutoriel est terminé !!
Un (des) trigger permettant d’historiser les mises à jour [et leurs détails] effectuées au sein des tables d’une base de données PostgreSQL / PostGIS a été créé
Ce tutoriel a été réalisé avec les logiciels PostgreSQL 9.6 et son extension spatiale PostGIS 2.3, ainsi qu’avec le logiciel SIG QGIS 2.14.9-Essen
Pour en savoir + …
L’idée de la réalisation de ce tutoriel nous est venue suite à un échange avec un client qui nous a interrogé sur envie de pouvoir effectuer un suivi des mises à jour effectuées au sein des données SIG qu’il gère.
Vous aimeriez que nous traitions un sujet, une problématique qui pourrait vous aider ?
N’hésitez pas à nous contacter et à nous soumettre votre besoin. Si nous le pouvons, nous y répondrons !
Vous avez aimé ?
Alors dites-le avec des , des likes, des tweets, des shares et des commentaires … !
On vous gâte…
Toujours + de tutoriels Impuls’Map !!
 Problématique posée et contexte : Notre SIGiste dispose de deux couches shapefile : une couche qui contient des polygones, une couche qui contient des points. Il existe une relation spatiale...
Problématique posée et contexte : Notre SIGiste dispose de deux couches shapefile : une couche qui contient des polygones, une couche qui contient des points. Il existe une relation spatiale...
 Le Syndicat Mixte du Beaujolais a acquis un webSIG chez GEOMAP-IMAGIS il y a quelques années, initialement basé sur une solution exploitant : PostGIS + QGIS + Mapserver + Webville...
Le Syndicat Mixte du Beaujolais a acquis un webSIG chez GEOMAP-IMAGIS il y a quelques années, initialement basé sur une solution exploitant : PostGIS + QGIS + Mapserver + Webville...

Tutoriel video by Impuls’Map pour apprendre à créer une carte web interactive, à partir de la librairie javascript Leaflet et exploitant des données geojson stockées dans des fichiers externes

Grâce à ce tutoriel, vous allez apprendre à créer un trigger pour pouvoir enregistrer et suivre les mises à jour effectuées au sein d’une base de données PostgreSQL. Et comme Impuls’Map est dédié aux SIG, nous effectuerons ce tutoriel au sein d’une base de données détenant l’extension spatiale PostGIS et à partir de données à dimension géographique, exploitables dans un SIG.